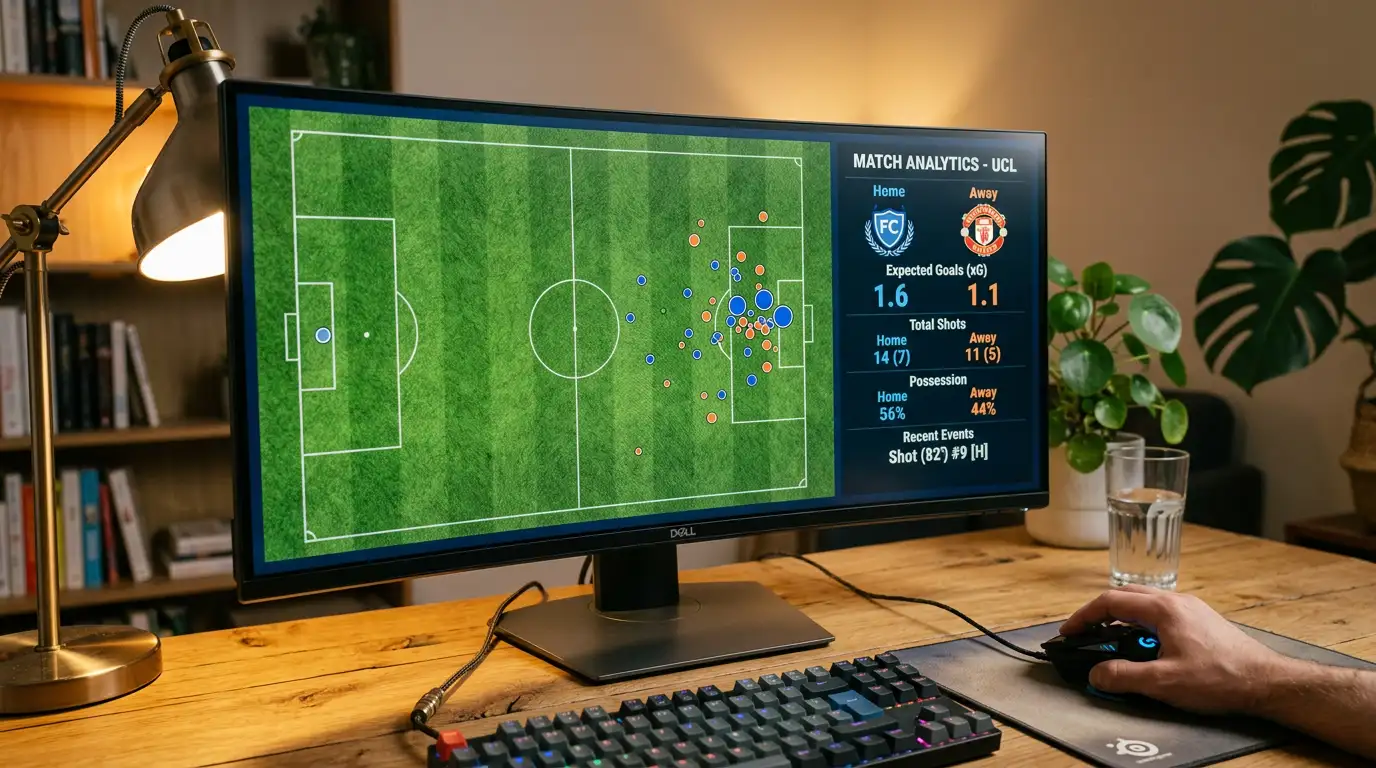
Wie ein 0:3 mit 2.4 xG mein Vertrauen in die Kennzahl wiederhergestellt hat
Ein Bayern-Heimspiel im November 2024 — Endstand 0:3 gegen den FC Bayern. Auf dem Papier ein Debakel. In der xG-Auswertung ein Spiel mit 2.4 erwarteten Toren für Bayern und 1.1 für den Gegner. Der Gegner hatte drei Schüsse, die zu Toren führten — Bayern hatte siebzehn Schüsse, die alle nicht trafen. Hätte ich nach diesem Spiel die Bayern-Quote für das nächste Heimspiel auf Bauchgefühl basiert, hätte ich Geld verloren. Mit dem xG-Wert im Hinterkopf habe ich Heimsieg getippt — und gewonnen. Genau das ist der Mehrwert von Expected Goals: nicht die Vorhersage einzelner Spiele, sondern die Korrektur der Wahrnehmung über Spielreihen hinweg.
xG ist die wichtigste Underlying-Statistik der letzten Jahre und wird in der Champions League seit 2019 von Anbietern, Klubs und Tippern routinemäßig genutzt. Die UEFA hat inzwischen eigene xG-Werte über das Datenpartner-Netzwerk integriert, DAZN zeigt sie in der Übertragung, und für lizenzierte Anbieter ist die Berechnung impliziter Tor-Wahrscheinlichkeiten ohne xG kaum noch denkbar. Wer die Mechanik der Kennzahl nicht versteht, tippt blind gegen ein Modell, das im Markt längst Standard ist.
Was xG misst — und was es eben nicht misst
Expected Goals ist die statistische Schätzung der Tor-Wahrscheinlichkeit eines Schusses, basierend auf historischen Daten zu vergleichbaren Schüssen. Ein Schuss aus 16 Metern, zentral, ohne Abwehrspieler in der Schussbahn, hat einen xG-Wert von etwa 0.15 — das heißt: Statistisch fällt aus dieser Position alle sieben Schüsse ein Tor. Ein Schuss aus 30 Metern unter Druck hat einen xG-Wert von 0.02. Ein Strafstoß hat 0.78.
Was xG nicht misst: Schuss-Qualität im Sinne von Technik, Wind, Tagesform, Rechte oder linke Fußneigung des Schützen, Position des Torwarts. Klassische xG-Modelle nehmen diese Variablen nicht auf — sie verwenden nur Schussposition, Winkel, Körperteil und Spielsituation (Standard, Kontersituation, offenes Spiel). Modernere Modelle wie xG2 oder Post-Shot-xG erweitern die Liste, aber die Grundkennzahl bleibt rein positionsbasiert.
Praktisch heißt das: Ein xG-Wert von 2.4 für ein Team in einem Spiel sagt aus, dass die Schussverteilung dieses Teams normalerweise zu 2.4 Toren führt. Ob das Team tatsächlich 0, 1, 2, 3 oder 4 Tore erzielt, hängt von der Schussqualität, der Form des Torwarts, dem Glück und einem Dutzend weiterer Faktoren ab. Wer xG als Vorhersage einzelner Tore liest, missversteht die Kennzahl. Wer sie als langfristige Erwartung über mehrere Spiele liest, hat ein Werkzeug, das die Form-Bewertung deutlich präziser macht als reine Tor-Statistik.
Champions-League-Spezifika der xG-Analyse
Die Champions League hat zwei xG-Eigenheiten, die in der Bundesliga schwächer wirken. Erstens: hohe Variabilität in der Schussqualität. K.-o.-Spiele werden taktisch konservativer geführt — weniger Schüsse, dafür höher gewichtete Schüsse aus Standardsituationen. In der K.-o.-Phase 2024/25 fielen 31 von 45 Spielen in die Drei-Tor-Klasse. Diese Tor-Inflation kommt nicht aus mehr Schüssen, sondern aus höherer durchschnittlicher Schussqualität pro Schuss.
Zweitens: Stilunterschiede zwischen Ligen. Ein Klub, der in der Bundesliga mit 1.4 xG pro Spiel agiert, kann in der CL je nach Gegner zwischen 0.8 und 2.2 xG liegen. Die Bundesliga-Form-xG ist deshalb nur bedingt übertragbar. Ich nutze für CL-Modelle ausschließlich CL-spezifische xG-Werte aus der laufenden und der vorherigen Saison — und korrigiere für Trainerwechsel und Stamm-Spieler-Ausfälle.
Praktisch baue ich für jedes CL-Spiel ein xG-Profil aus drei Datensätzen: die jeweils letzten fünf CL-Pflichtspiele, die letzten zehn nationalen Liga-Spiele (gewichtet) und die direkten Begegnungen der Klubs aus den letzten drei Jahren. Diese Mischung ist robuster als reine CL-Daten, die bei selten antretenden Klubs zu dünn sind.
Welche xG-Modelle sich unterscheiden und wann das relevant ist
Es gibt nicht ein xG-Modell, sondern Dutzende. Die größten Datenanbieter — Opta, StatsBomb, Wyscout, Football Reference, Understat — kalkulieren mit unterschiedlichen Ausgangsdaten und unterschiedlichen Modellen. Der xG-Wert eines Spiels kann zwischen den Anbietern um 15 bis 25 Prozent variieren — was bei einem Modell mit Schwellenrelevanz (etwa für Über/Unter-Linien) nicht trivial ist.
Die wichtigsten Unterschiede liegen bei der Behandlung von Standards (Eckbälle, Freistöße), Konterchancen und Strafstößen. Manche Modelle weisen Strafstöße einen festen Wert von 0.76 oder 0.78 zu, andere kalkulieren ihn dynamisch nach Schütze. Manche schließen geblockte Schüsse aus, andere zählen sie mit reduziertem xG-Wert.
Wenn ich xG-Werte aus mehreren Quellen vergleiche und die Streuung über 20 Prozent geht, wird die Kennzahl unzuverlässig — meistens, weil ein Schuss-Datensatz unterschiedlich kategorisiert wurde. In solchen Fällen warte ich, statt zu setzen. Ein dünner xG-Datensatz ist schlimmer als kein xG-Datensatz, weil er Sicherheit suggeriert, die nicht da ist.
Wie xG die Über/Unter- und BTTS-Quoten verändert
Mein Standardrechner für Tor-Linien nutzt xG als Hauptinput. Aus den xG-Werten beider Mannschaften berechne ich eine Poisson-Verteilung der Toranzahl — die ergibt für jede Linie eine Wahrscheinlichkeit. Bei einem CL-Spiel mit 1.6 xG für Heim und 1.1 xG für Auswärts kommt die Wahrscheinlichkeit für Über 2.5 auf etwa 53 Prozent, für Über 3.5 auf etwa 30 Prozent, für BTTS-Ja auf etwa 60 Prozent.
Wenn der Anbieter Über 2.5 für 1.85 anbietet — implizite Wahrscheinlichkeit 54 Prozent — habe ich kaum Edge. Bietet er Über 2.5 für 2.05 — implizite Wahrscheinlichkeit 49 Prozent — und mein Modell sagt 53 Prozent, dann ist das ein Value-Setup mit etwa 8 Prozent Edge vor Wettsteuer.
Wichtig: Diese Rechnung funktioniert nur, wenn meine xG-Werte tatsächlich die wahre Tor-Verteilung approximieren. Bei Spielen mit hohem Standard-Anteil oder bei Klubs mit ungewöhnlich konzentrierten Schuss-Profilen ist die Poisson-Annahme verzerrt. Ich nutze für diese Fälle eine angepasste Verteilung, die die Über-Streuung der CL-Spiele um etwa 8 Prozent berücksichtigt.
Wo xG schlicht versagt — und was ich in solchen Fällen mache
Ein xG-Modell scheitert systematisch in drei Szenarien. Erstens: kleine Stichprobe. Wenn ein Klub in seiner letzten CL-Saison nur drei oder vier Spiele bestritten hat, ist der xG-Mittelwert zu volatil, um darauf zu wetten. Zweitens: Stilbruch nach Trainerwechsel. Ein Klub, der vor zwei Wochen den Trainer gewechselt hat, hat keine xG-Historie unter der neuen Spielidee. Drittens: Spitzen-Spielmacher fehlt. Ein Klub, dessen xG-Profil zu 35 Prozent von einem einzigen Spieler getragen wird, kollabiert ohne diesen Spieler — egal was der Saisondurchschnitt sagt.
In diesen drei Szenarien tippe ich entweder gar nicht oder reduziere den Einsatz auf ein Drittel der üblichen Stake. Disziplin ist hier wichtiger als Tipp-Volumen. Wer in jeder Spielsituation einen Tipp findet, gewinnt langfristig nicht — er verliert nur in einem zufällig wirkenden Muster.
xG ist im Mai 2026 das anerkannteste Werkzeug der Modell-Wett-Welt — aber das macht es nicht zu einem Allheilmittel. Ich nutze es für rund 70 Prozent meiner CL-Tipps, für die anderen 30 Prozent vertraue ich auf direkte Form-Filter, Aufstellungs-Analyse oder Quoten-Vergleiche. Wer xG mit Markt-Bewegungen kombinieren will, sollte sich die mathematischen Grundlagen der KI-Prognose Champions League ansehen — der nächste Schritt nach dem klassischen xG-Rechnen.
Welche kostenlosen xG-Quellen taugen für CL-Wetten?
Wie kombiniere ich xG mit Marktbewegung der Quoten?
Material erstellt vom Team QUOTENPOTT



